
This website uses cookies to ensure you get the best experience. Learn more
OCR & PDF/A Archiving add-on
Use the PDF Converter Professional add-on to add Optical Character Recognition (OCR) and PDF/A support to the PDF Converter for SharePoint and PDF Converter Services. These technologies make image-based content discoverable, and allow documents to be archived in the PDF/A 1b, 2b and 3b formats required by regulatory bodies.

Muhimbi’s products are trusted by thousands of high-profile organisations.
Optical Character Recognition
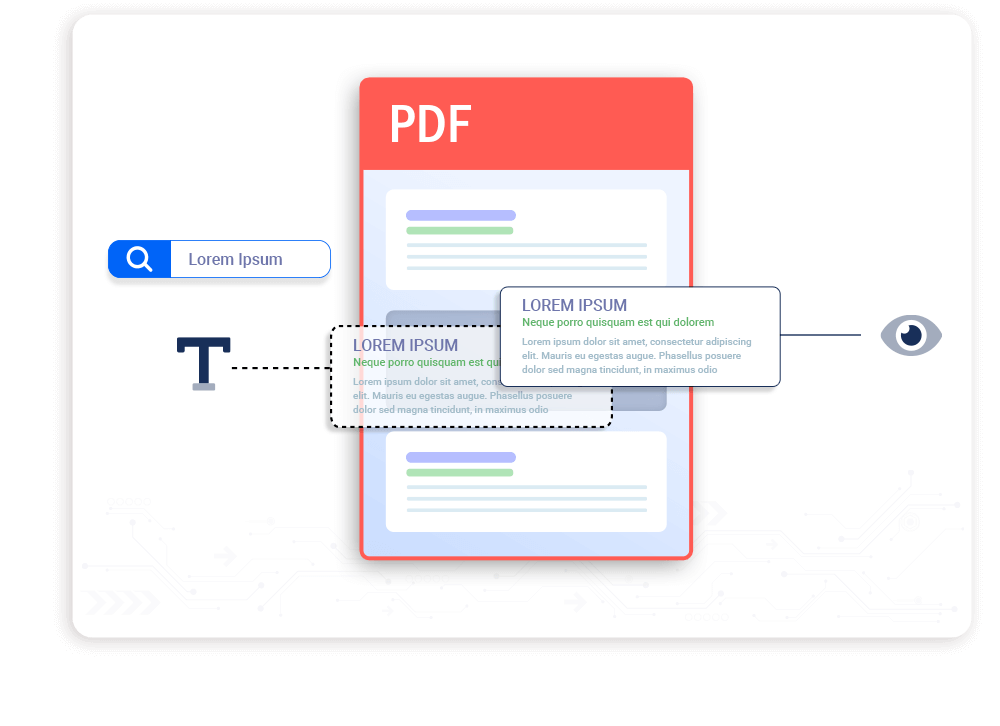
Image based content such as scans and faxes are typically stored as ‘bitmaps’, a visual representation of the original document, but without all the important information such as the document’s text in a computer readable format.
As a result the document looks perfectly normal to humans, who have text recognition built into their brains, but computers cannot make any sense of it. By applying OCR, the text is recognised and placed on a hidden layer in the document.
The resulting document still looks the same as before, but it can now be indexed by search engines, and PDF readers can be used to search inside it. Documents that were lost before are now fully discoverable.
Convert to PDF/A

Many organisations are governed by a regulatory body specific to their industry. The SEC, FTC, FCC, EPA, NLRB, IRS, EEOC, OSHA, and OFCOM are some examples. These regulatory bodies often dictate document retention periods and standards.
One of the standards require documents to be archived in the PDF/A format. PDF/A is different from the regular PDF format generated by most applications as it is specifically intended for long term archiving to make sure that – whatever technology is in use in 20 years’ time – documents can still be processed and accessed with relative ease.
By using the PDF Converter Professional add-on, all file formats supported by the Muhimbi PDF Converter - including Office, Email, HTML and others - can be converted to fully compliant PDF/A files.
Muhimbi has a 4.5+ rating in Trustpilot and App Store.
Ken T
Using Muhimbi for several projects. From the tools our team evaluated, Muhimbi provides the most accurate rendering and flexible attachment processing.
Michael Dockray
Great support to resolve our problem watermarking documents in Power Automate. Solved the issue and gave valuable insights into best practices.
Andrew Wilkie
We've used Muhimbi for 8 years in tandem with Nintex Workflow. The technical support is top notch, quick to respond and eager to assist.
Arren Quigle
As a new user I ran into a technical issue. Yash assisted via chat and screen share to solve it in 2 minutes. It was a user error.
Paul
Complex scenario to connect 2 K2 servers to 1 SharePoint instance. Support was very responsive over several deeply technical sessions.
Mikael Råstock
A fantastic product. Watermarking approved documents, merging documents, archiving as pdf/a. Premium support instantly from their helpdesk.
Jari Nguyen
We are really happy to recommend Muhimbi as it reduced development time, and costs to convert email into PDF directly from Microsoft Flow.
Rich Piazza
Yash was very helpful in the whole process from proof of concept to production. Available and willing to work with my team!!!!
Sonia Bilodeau
The call back is quick, and the service is efficient. I felt confident. Thank you!
Jesus Martinez
Had no experience, but a sales engineer listened to our requirements and provided a working solution. Implementation was extraordinarily easy!
Rick Backus
Problem solved in 18 minutes. Yash was very helpful with both support and explaining pricing.
l. Berzan
Excellent product, excellent support with a really quick resolution!